Construct#
Initializing a Document object is easy. This chapter introduces the ways of constructing both empty and filled Documents. You can also construct Documents from bytes, JSON, or Protobuf message as introduced in the next chapter.
Construct an empty Document#
from docarray import Document
d = Document()
<Document ('id',) at 5dd542406d3f11eca3241e008a366d49>
Each Document has a unique random id to identify it. It can be used to access the Document inside a DocumentArray.
Tip
The random id is the hex value of UUID1. To convert it into the a UUID string:
import uuid
str(uuid.UUID(d.id))
Though possible, we don’t recommended modifying the .id of a Document frequently, as this leads to unexpected behavior.
Construct with attributes#
This is the constructor’s most common use: initializing a Document object with the given attributes:
from docarray import Document
import numpy
d1 = Document(text='hello')
d2 = Document(blob=b'\f1')
d3 = Document(tensor=numpy.array([1, 2, 3]))
d4 = Document(
uri='https://docs.docarray.org',
mime_type='text/plain',
granularity=1,
adjacency=3,
tags={'foo': 'bar'},
)
Don’t forget to leverage autocomplete in your IDE.
<Document ('id', 'mime_type', 'text') at a14effee6d3e11ec8bde1e008a366d49>
<Document ('id', 'blob') at a14f00986d3e11ec8bde1e008a366d49>
<Document ('id', 'tensor') at a14f01a66d3e11ec8bde1e008a366d49>
<Document ('id', 'granularity', 'adjacency', 'mime_type', 'uri', 'tags') at a14f023c6d3e11ec8bde1e008a366d49>
Tip
When you print() a Document, you get a string representation like <Document ('id', 'tensor') at a14f01a66d3e11ec8bde1e008a366d49>. This shows the Document’s non-empty attributes as well as its id. All of this helps you understand the content of that Document.
<Document ('id', 'tensor') at a14f01a66d3e11ec8bde1e008a366d49>
^^^^^^^^^^^^^^ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
| |
| |
non-empty fields |
Document.id
You can also wrap keyword arguments into a dict. The following ways of initialization have the same effect:
d1 = Document(
uri='https://docs.docarray.org', mime_type='text/plain', granularity=1, adjacency=3
)
d2 = Document(
dict(
uri='https://docs.docarray.org',
mime_type='text/plain',
granularity=1,
adjacency=3,
)
)
d3 = Document(
{
'uri': 'https://docs.docarray.org',
'mime_type': 'text/plain',
'granularity': 1,
'adjacency': 3,
}
)
Nested Document#
See also
This section describes how to manually construct a nested Document, for example to hold different modalities, like text and image.
To construct multimodal Documents in a more comfortabe, readable, and idiomatic way you should use DocArray’s dataclass API.
To learn more about nested Documents, please read Nested Structure.
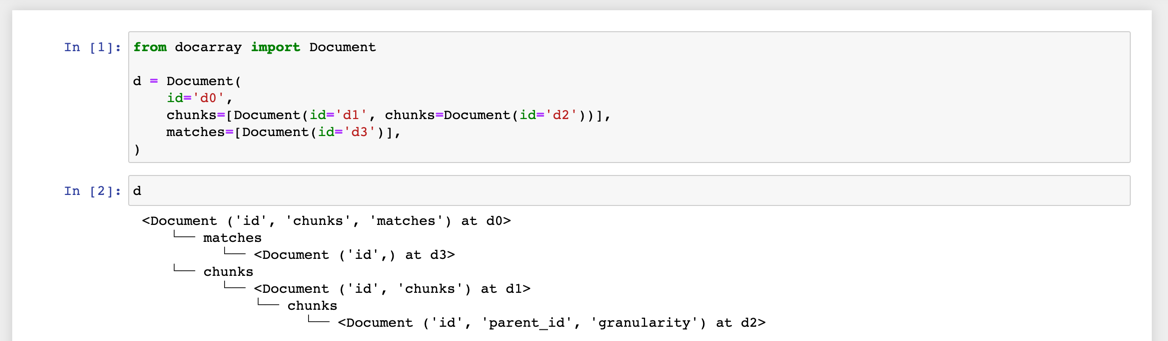
Documents can be nested inside .chunks and .matches. You can specify this nested structure directly during construction:
from docarray import Document
d = Document(
id='d0',
chunks=[Document(id='d1', chunks=Document(id='d2'))],
matches=[Document(id='d3')],
)
print(d)
<Document ('id', 'chunks', 'matches') at d0>
For a nested Document, printing its root doesn’t give much information. Instead, you can use summary() – for example, d.summary() gives a more intuitive overview of the Document’s structure.
<Document ('id', 'chunks', 'matches') at d0>
└─ matches
└─ <Document ('id',) at d3>
└─ chunks
└─ <Document ('id', 'chunks') at d1>
└─ chunks
└─ <Document ('id', 'parent_id', 'granularity') at d2>
When using in Jupyter notebook/Google Colab, Documents are automatically prettified.
Unknown attribute handling#
If you give an unknown attribute (i.e. not one of the built-in Document attributes), it is automatically “caught” into the .tags attribute. For example:
from docarray import Document
d = Document(hello='world')
print(d, d.tags)
<Document ('id', 'tags') at f957e84a6d4311ecbea21e008a366d49>
{'hello': 'world'}
You can change this catch behavior to drop (silently drop unknown attributes) or raise (raise an AttributeError) by specifying unknown_fields_handler.
Resolve unknown attributes with rules#
You can resolve external fields into built-in attributes by specifying a mapping in field_resolver. For example, to resolve the field hello as the id attribute:
from docarray import Document
d = Document(hello='world', field_resolver={'hello': 'id'})
print(d)
<Document ('id',) at world>
You can see id of the Document object is set to world.
Copy from another Document#
To make a deep copy of a Document, use copy=True:
from docarray import Document
d = Document(text='hello')
d1 = Document(d, copy=True)
print(d == d1, id(d) == id(d1))
True False
This indicates d and d1 have identical content, but they are different objects in memory.
If you want to keep the memory address of a Document object while only copying the content from another Document, you can use copy_from().
from docarray import Document
d1 = Document(text='hello')
d2 = Document(text='world')
print(id(d1))
d1.copy_from(d2)
print(d1.text)
print(id(d1))
4479829968
world
4479829968
What’s next?#
You can also construct Documents from bytes, JSON, and Protobuf message. These methods are introduced in the next chapter.
